CORE for Tokenization and Format Preserving Encryption
Tokenization is the process of replacing sensitive data with non-sensitive data, referred to as a token. This process is commonly used for credit card numbers, social security numbers and phone numbers.
This section describes CORE support for Tokenization and Format Preserving Encryption ("FPE"). The different API sets mentioned in this document all have support for application level encryption. Encryption methods and modes follow the standard ones (symmetric and asymmetric) and best practices.
Unlike these encryption methods, tokenization and FPE is a unique mode of encryption where specific rules are enforced on the cipher text.
In general, the recommendation is to use standard encryption algorithms. Tokenization should be used in special cases, such as:
-
When the ciphertext needs to get transported via various systems that expect the same type or format of the plaintext. Some systems even require that the format of the ciphertext passes various validation schemes (such as the Luhn check for credit cards).
-
When the ciphertext needs to have the same result on every encryption of the same plaintext, such as when performing a lookup from a database for the record key.
It is possible to use a hybrid approach. For example, tokenization for lookup and encryption for the rest of the information.
Tokenization Basics
CORE supports tokenization of the following data types:
-
Credit/Debit/Pre-paid card number
-
Social Security Number (SSN)
-
US phone number
-
Email address
-
Basic data types: string, number, date, time, boolean, byte array
Each data type input (plain) preserves its own specific output (cipher) format; that is, a tokenized date will appear as a date, a tokenized credit card number will look and pass all credit card number validity tests, and so forth.
The API tokenization formats for the different data types are shown in the table below.
| Data Type | Standard Tokenization | Validity Checks |
|---|---|---|
|
Credit/Debit/Pre-paid card number
|
Tokenize the cleartext credit card number to a token with the same number of digits. For example, 1234123412341234 will look as 4321432143214321. |
Card number is between 12 and 19 digits. Card number must be valid. The tokenized value is Luhn compliant. |
|
Social Security Number (SSN) |
Tokenize the cleartext SSN to a token with the same number of digits. For example, 123121234 will look like 321214321. You can specify a format for the SSN: ###-##-#### or ######### or #####???? The # characters get encrypted. Hyphens are passed as-is. Question marks can be used to mark the last digit group to pass the last four digits as-is. |
SSN number is 9 digits. SSN can be any number except:
|
|
US phone number |
Tokenize a USA phone number. You can specify a format for the phone number: ###-###-#### The # characters get encrypted. Hyphens are passed as-is. Hyphens are not required to be used in the value. |
US phone number is 10 digits. It is validated by checking the format aaa-bcc-dddd, where aaa > 200, b >= 2, and cc is not 11. |
|
Email address |
Tokenize an email address. You must specify the maximum size for the tokenized email address using the maxSize parameter (applies to EMAIL data type only). maxSize: Specify a single integer that must be greater than or equal to the number of characters of the longest email to be tokenized within the range: 40 to 254. |
Must be a valid email address format and must contain an @ as a separator. Can contain maximum 70 characters, ignoring the @ separator. Can contain these characters: |
|
String |
Tokenize a string value. |
The string must be Unicode (as defined by ISO/IEC 10646). Content-Type: application/json; charset=UTF-8 |
|
Generic number |
Tokenize a plain number. Negative values are prefixed with a minus sign (-). Positive values can be prefixed with plus sign (+), but it is not mandatory and will not fail the operation. Leading zeros are ignored and will not fail the operation. |
The number can be of type: short:
integer:
long:
float: 32-bit (7 digits)
double: 64-bit (15-16 digits)
decimal: 128-bit (28-29 digits)
|
|
Date/Time/Timestamp |
Tokenize a plain date or time with the following pattern: Date pattern: yyyy-[m]m-[d]d
Time pattern: hh:mm:ss
Timestamp pattern: yyyy-mm-dd hh:mm:ss.fffffffff
|
The output is any valid date, time, or timestamp. |
|
Boolean |
Tokenize a BOOLEAN value: true or false. |
The tweak needs to change per input value to return a random tokenized true or false value. |
|
Byte Array |
Tokenize a byte array to an array of the same size using the Java API. |
Format strings
A format string is used to define the tokenization format. The format string is used for SSN and US phone data types as shown in the table above.
The characters of the format string are specified as follows:
- The # digit will be tokenized.
- The ? digit will not be tokenized (i.e., it passes as-is).
- Hyphens are copied to the output.
Note
The same format string used to tokenize a value must be used to detokenize that value. If the detokenize input does not match the format string that was used for tokenizing that value, the response produces an error.
For examples of tokenization of all the supported data types, see REST API Tokenization Examples with cURL
Algorithms in Use
Unbound’s application-level encryption uses two types of encryption keys:
-
Asymmetric ECC
 Elliptic-curve cryptography - an approach to public-key cryptography based on the algebraic structure of elliptic curves over finite fields P256 for the master keys.
Elliptic-curve cryptography - an approach to public-key cryptography based on the algebraic structure of elliptic curves over finite fields P256 for the master keys.The master keys are secured by CORE with MPC
Multiparty computation - A methodology for parties to jointly compute a function of their inputs while keeping those inputs private.. -
Symmetric AES 256 as session keys.
The AES-based session keys are used to encrypt the data. They are derived from the master keys using ECC
Elliptic-curve cryptography - an approach to public-key cryptography based on the algebraic structure of elliptic curves over finite fields PRF protocol.
The key derivation and the encryption mechanisms use tweakable encryption schemes. The tweak should be based on the database identifiers such as the Record Key ID. For more information on tweakable encryption see Tweakable_block_ciphers.
One-way Tokenization
Besides tokenization which allows detokenization to get the original value, CORE also supports one-way tokenization which creates a unique searchable token from any value. This can be used for DB lookups, without the option to ever decrypt the value.
Another way to implement one-way encryption is to use the plain data as the tweak. For example, take the plain credit card number and use it as both the tweak and the input. This approach is a deterministic![]() Calculation that each time results in the same value tokenization of the original credit card number but does not allow decryption since you do not have the plain credit card number (i.e., you do not have the tweak). Another example, is to use a different tweak for different columns in the database. In this case, the tweak may be based on the scheme name and database identifiers, e.g., SchemeName.TableName.ColumnName.
Calculation that each time results in the same value tokenization of the original credit card number but does not allow decryption since you do not have the plain credit card number (i.e., you do not have the tweak). Another example, is to use a different tweak for different columns in the database. In this case, the tweak may be based on the scheme name and database identifiers, e.g., SchemeName.TableName.ColumnName.
Tokenization and Key Rotation
Key rotation is one of the building blocks of every encryption system and is required with different encryption regulations and best practices. The CORE platform supports both manual and automatic key rotation as well as complete traceability (backwards and forwards traceability) of the key history for each key. The details of the exact key used for the encryption of existing data as well as the process of decrypting with the exact key version is application dependent and is managed by the encryption application, supported by CORE for key rotation and versioning.
The process of tokenization presents a specific challenge with key versioning as there is not enough space in the ciphertext (the token) to keep information about the key version. Therefore, it is required to perform one of the following operations:
-
Whenever the key needs to be rotated perform the following (this method is usually denoted as re-encryption):
-
Execute key-rotation to create a new key.
-
Decrypt data using the old key.
-
Encrypt data using the new key.
-
Store the timestamp with the database record, for example:
-
Everything tokenized in 2019 is done with Key1.
-
Everything tokenized in 2020 is done with Key2.
-
Use the matching key to detokenize, based on data timestamp.
-
Keep the key version in the database, for example:
-
For record1, store the unique ID of Key1.
-
For record2, store the unique ID of Key2.
-
Use the matching key to detokenize using the key ID stored in the DB.
Developing with the Tokenization API
Unbound provides 3 options for using CORE tokenization:
-
Use the Java tokenization SDK.
-
Use CORE REST
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API tokenization functions. -
Use the CORE Tokenization container service.
Using the Java API
Review Developing in Java and Java Provider JAR and Security Class for details about the different methods to include the Unbound Java API in your applications and other general best practices and guidelines of using CORE with Java.
Implementation of the tokenization is contained in two classes:
-
com.dyadicsec.advapi.SDEKey– main class for all encryption functions. -
com.dyadicsec.advapi.SDESessionKey– used to allow reuse of DEKData Encryption Key - the key that encrypts the database. See also - KEK. (Data Encryption Keys) for performance improvements.
Click here for detailed API information about the SDEKey and SDESessionKey APIs.
Use the Unbound API as follows:
-
Use it to tokenize data before inserting or updating data to the database.
-
Use it to create search tokens when searching for data in the database.
-
Use it to detokenize data after retrieving it from the database.
You control the encryption properties using the following options:
-
Encryption can be order-preserving (select the matching
encryptOrderPreservingfunction) or type-preserving (select the matchingencryptTypePreserving). -
The scope of the encryption depends on the
tweakparameter provided to all functions; all values that may be compared (used in the WHERE or HAVING clause) in a single query should use the sametweakvalue.
Use the following table to set the encryption properties.
| Property | Description | Tweak Granularity | Function to Use |
|---|---|---|---|
| Default encryption | Fully secured encryption. No information whatsoever is revealed about the plaintext. | Unique per row, e.g., row ID | SDEKey.encryptTypePreserving |
| Allows search by EQUALS | This encryption method is fully secured when all items are unique in this attribute and this table. When the same item repeats multiple times in this attribute in this table, it is possible to detect which items are the same. | Unique per column, e.g., column name | SDEKey.encryptTypePreserving |
| Allows search by equals and using the field for JOIN | This encryption method is fully secured when all items are unique in the entire database. When the same item appears multiple times in the database, it is possible to detect which items are the same. | The same tweak for all involved columns, e.g., join name | SDEKey.encryptTypePreserving |
| Allows search by ORDER | This encryption method reveals the lexicographic order between encrypted items in this attribute and this table. | Unique per column, e.g., column name | SDEKey.encryptOrderPreserving |
| Allows search by ORDER and using the field for JOIN | This encryption method reveals the lexicographic order between encrypted items in the entire database. | The same tweak for all involved columns, e.g., join name | SDEKey.encryptOrderPreserving |
| Only find is needed (no decryption) | This encryption method is fully secured when all items are unique in this attribute and this table. When the same item repeats multiple times in this attribute in this table, it is possible to detect which items are the same. This method provides additional protection since decryption is not possible. | Unique per column, e.g., column name | SDEKey.encryptPRF |
| Only find is needed (no decryption), the field is used for JOIN | This encryption method is fully secure when all items are unique in the entire database. When the same item appears multiple times in the database, it is possible to detect which items are the same. This method provides additional protection since decryption is not possible. | The same tweak for all involved columns, e.g., join name | SDEKey.encryptPRF |
| Arbitrary objects and files | Application-level encryption can also be used to encrypt arbitrary objects and files, with an easy to use API. | For more information contact Unbound Support |
Once you use the application-level encryption, you may need to change the type of your original DB column as the result of the encryption function may be of a different type from the original. Use the following table to understand what needs to be changed and how.
| Type | For all operations except “ORDER by” | For “ORDER by” operation |
|---|---|---|
| boolean | No change | Not relevant |
| string (varchar) | No change | Column length increase |
| int, tinyint, smallint, short | No change |
Change to Long |
| timestamp, tinyint | Change to short |
Need to add new string (varchar) column |
| BLOB (bytearray) | No change |
Not relevant |
Caching Data Encryption Keys (DEK![]() Data Encryption Key - the key that encrypts the database. See also - KEK.)
Data Encryption Key - the key that encrypts the database. See also - KEK.)
To improve performance and allow flexibility of DEK![]() Data Encryption Key - the key that encrypts the database. See also - KEK., the Unbound application-level encryption allows to cache it.
Data Encryption Key - the key that encrypts the database. See also - KEK., the Unbound application-level encryption allows to cache it.
Utilize this feature with the SDESessionKey class. You can generate a session-key based on a tweak value and use this session-key instance instead of the string tweak value. This option allows you to control the lifespan of the DEK![]() Data Encryption Key - the key that encrypts the database. See also - KEK. keys. You can regenerate it on each encryption operation (using the
Data Encryption Key - the key that encrypts the database. See also - KEK. keys. You can regenerate it on each encryption operation (using the tweak string value) or keep it as a session-key for the entire application run time, or anything in-between.
Generate a session key using the generateSessionKey function of the SDEKey class.
Using REST API
The CORE REST![]() Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API includes support for tokenization and detokenization. See the following links for more details:
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API includes support for tokenization and detokenization. See the following links for more details:
Using the Tokenization Container
This section describes an implementation of CORE in a Docker container solution for tokenization.
Set up CORE
-
To install CORE, refer to the CORE Installation Guide.
-
Create a partition for tokenization.
-
If using the command line, see Create a Partition.
-
If using the UI, see Create New Partition.
-
-
In the CORE web UI, access the Clients screen.
-
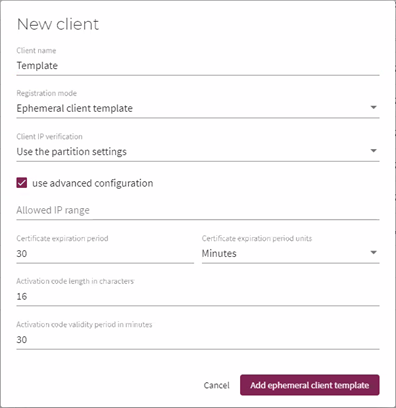
Create a client. The Registration mode field can be set to:
-
Activation code – single client activation.
-
Ephemeral client template – This mode removes the need to create a new client for each container.
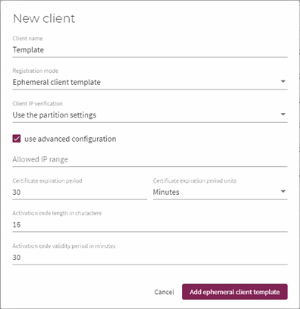
Note
It is recommended to change the Certificate expiration period and the Activation code validity period to relevant values for your organization. For example, you may want the certificate to be valid for 1 year and the activation code for 1 month. -
-
On the Keys and Certificates screen, create a PRF key.
Start the Tokenization Service
-
Retrieve the docker image. This container contains a CORE client.
-
Configure the client.conf file with the names of the CORE Entry Point servers.
-
Start docker. The following example shows 3 CORE server pairs and sample path to the client.conf file.
-
Verify that docker is running.
-
If needed, you can check the tokenization log.
docker pull unboundukc/tokenization
servers=https://ep1,https://ep2,https://ep3
sudo docker run -d -e PARTITION="<PARTITION-NAME>" -e TEMPLATE_NAME="<TEMPLATE-NAME>" -e CODE="<ACTIVATION-CODE>" --add-host <ENTRY-POINT1>:<EP1-IP-ADDRESS> --add-host <ENTRY-POINT2>:<EP2-IP-ADDRESS> --add-host <ENTRY-POINT3>:<EP3-IP-ADDRESS> -v /<path-to-file>/client.conf:/etc/ekm/client.conf -p8080:8080 unboundukc/tokenization
Note
The paths specified in the docker command are the location on the local device and the destination in the docker container.
Alternatively, some of the parameters can be stored in a file, called env_variables.env. This file can then be included in the command line with:
--env-file env_variables.env
For example, here are the contents of the file.
PARTITION=part1
TEMPLATE_NAME=demo
CODE=8457268343906079
PASSWORD=Password1!
Note
If the user has a password, you can add the following either to the command line: -e USER=<USER NAME> -e PASSWORD=”<USER PASSWORD>” or add it to the environment variables file.
If you are using an active client, you can use the following commands:
sudo docker run -d -e PARTITION="<PARTITION-NAME>" -e CLIENT_NAME="<CLIENT-NAME>" -e CODE="<ACTIVATION-CODE>" --add-host <ENTRY-POINT1>:<EP1-IP-ADDRESS> --add-host <ENTRY-POINT2>:<EP2-IP-ADDRESS> --add-host <ENTRY-POINT3>:<EP3-IP-ADDRESS> -v /<path-to-file>/client.conf:/etc/ekm/client.conf -p8080:8080 unboundukc/tokenization
curl <Container-IP-Address>/api/v1/info
Example response:
{
"user": "User",
"partition": "part1",
"epUrls": [
"https://ep3",
"https://ep1",
https://ep2
],
"ukcHealthy": true
}
sudo docker exec -it <CONTAINER ID> less /var/log/tokenization.log
Troubleshooting
The following sections contain troubleshooting for various issues that may occur.
User not logged in or incorrect password
In this case, you get the following error:
{
"timestamp": "2020-09-30T13:34:54.504396800",
"status": 401,
"type": "UNAUTHORIZED",
"path": "http://localhost:8080/api/v1/keys/PRF/tokenizex",
"message": "Authentication failure",
"details": "com.dyadicsec.cryptoki.CKR_Exception: Library errorCode=0x101: User is not logged in"
}
Check that the username and password are correct and that the user has permissions to access the system.
Key not found
In this case, you get the following error:
{
"timestamp": "2020-09-30T14:12:08.125529300",
"status": 404,
"type": "NOT_FOUND",
"path": "http://localhost:8080/api/v1/keys/ECC/tokenize",
"message": "Key not found"
}
Check that the key exists, and the correct key was specified.
CORE is not running
In this case, you get the following error when trying to run tokenization requests:
{
"timestamp": "2020-09-30T14:14:08.383047300",
"status": 503,
"type": "SERVICE_UNAVAILABLE",
"path": "http://localhost:8080/api/v1/keys/ECC/tokenize",
"message": "UKC isn't running",
"details": "java.security.ProviderException: com.dyadicsec.cryptoki.CKR_Exception: Library errorCode=0x30: UKC error"
}
Start CORE and try again.
Key is not PRF type
In this case, you get the following error:
{
"timestamp": "2020-09-30T15:11:30.500566600",
"status": 400,
"type": "BAD_REQUEST",
"path": "http://localhost:8080/api/v1/keys/c093b7d3c2099e67/detokenizex",
"message": " Cryptographic failure",
"details": "com.dyadicsec.cryptoki.CKR_Exception: Library errorCode=0x63: Cryptographic key type is inconsistent with mechanism"
}
Check the type of the key that was sent.
REST API Tokenization Examples with cURL
The tokenization rules for each supported data type are presented below along with a cURL example showing the tokenization parameters.
These examples are tested on Ubuntu 18.04 using CORE 2.0.2103.
Prerequisites
The prerequisites and assumptions are:
-
CORE URL e.g., https://192.168.0.12:443
-
Partition name e.g., test2 (see Create New Partition.)
-
Partition user credentials
-
Username: <name>@<partition> e.g., user1@test2
-
Password: e.g., Password1!
-
PRF key UID designated for tokenization/detokenization, e.g., prf1
-
Authorization type is Basic Auth, e.g., user1@test2:Password1!
-
In cURL, Basic Auth is encoded in Base64 format.
-
Single Item Tokenization
Tokenize single items with a PRF key using the Tokenize REST![]() Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
URL format: POST <EP URL>/api/v1/keys/:keyId/tokenize?partitionId=<partiton name>
-
Example:
POST https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2
Query params:
-
Partition ID – name of the partition that has a PRF tokenization key.
Path variables:
-
KeyID – name or UID of the PRF tokenization key.
Body params – specify the tokenization parameters in JSON:
-
dataType – specified below. Mandatory.
-
tweak – mandatory. Changes the tokenization effect when applied to the same data. For example, it is good practice to use a different tweak for different columns in the DB. In this case, the tweak may be based on the scheme name and database identifiers, e.g., SchemeName.TableName.ColumnName.
-
value – the object of tokenization. Mandatory.
-
format – specifies how the string in the value parameter should be formatted. Applies to structured data types, such as Social Security Number (SSN) and USA Phone Number – see the examples below.
-
maxSize – the maximum size of the output of the item (tokenized email address). Applies to EMAIL data type only. The value must be greater than or equal to the number of characters of the longest email to be tokenized. See the example below.
Email Address
Tokenize an email address using the following rules:
- value: Must be a valid email address format and must contain an @ as a separator.
-
Can contain maximum 70 characters, ignoring the @ separator.
-
Can contain these characters: A-Z, a-z, 0-9, .!#$%&*+-/={|}~(),:;<>[]
-
maxSize: Specify a single integer within the range: 40 to 254.
Note
maxSize must be greater than or equal to the number of characters of the longest email to be tokenized.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "EMAIL",
"tweak": "1word",
"value": "jane.doe@organization.com",
"maxSize": "40"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "ghoZR8bGYT5@BEyt6Y1rZbGEbxgK2Cz0vw7G.ir"
}
Social Security Number (SSN)
Tokenize an SSN, which uses the format parameter according to the following rules:
-
value: 9 digits.
-
format: ###-##-#### or ######### or #####????
Hyphens are passed as-is. Question marks can be used to mark the last digit group to pass the last four digits as-is.
-
SSN can be any number except the following:
-
Numbers with all zeros in any digit group, e.g., 000-##-####, ###-00-####, or ###-##-0000.
-
Numbers in the first digit group that are 666 or range from 900 to 999 (Individual Taxpayer Identification Number).
cURL Example
curl --location --request POST https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "SSN",
"tweak": "oneword",
"value": "123-12-1234",
"format": "###-##-####"
}'
Example Response
{
"uid": "0x0095434475f7141108",
"tweak": "oneword",
"value": "131-14-9217"
}
Credit Card
Tokenize a credit card/debit card/pre-paid card number using the following rules:
- value: Card number must be valid.
-
Number of digits: 12 to 19.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "CREDIT_CARD",
"tweak": "oneword",
"value": "378282246310005"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "026202566688935"
}
USA Phone Number
Tokenize a USA phone number using the following rules:
-
value: 10 digits.
-
format: ###-###-####
-
Hyphens are not required to be used in the value, but if used, then are passed as-is.
-
Validates the value by checking the format aaa-bcc-dddd, where aaa > 200, b >= 2, and cc is not 11.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "US_PHONE",
"tweak": "oneword",
"value": "202-555-0165",
"format": "###-###-####"
}'
Example Response
{
"uid": "0x0095434475f7141108",
"tweak": "oneword",
"value": "511-995-2085"
}
STRING
Tokenize a string using the following rules:
-
value: Any type of character.
-
String must be Unicode (as defined by ISO/IEC 10646).
-
Content-Type: application/json; charset=UTF-8
UTF-8 is character encoding scheme that includes and is backwards compatible with ASCII
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json; charset=UTF-8' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "STRING",
"tweak": "any number of words",
"value": "a_b"
}'
Example Response
{
"uid": "0x0095434475f7141108",
"tweak": "any number of words",
"value": "!������"
}
BOOLEAN
Tokenize a boolean data type using the following rules:
-
value: true/false
-
tweak: Tokenize response returns random true or false values if the tweak changes per input value.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "BOOLEAN",
"tweak": "2words",
"value": "true"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "2words",
"value": "false"
}
SHORT
Tokenize a short data type using the following rules:
-
value range is from -32768 to +32767
-
Negative values are prefixed with a minus sign (-).
-
Positive values can be prefixed with plus sign (+), but it is not mandatory and will not fail the operation.
-
Leading zeros are ignored and will not fail the operation.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "SHORT",
"tweak": "oneword",
"value": "+12345"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "10947"
}
INTEGER
Tokenize an integer data type using the following rules:
-
value range is from -2147483647 to 2147483647
-
Negative values are prefixed with a minus sign (-).
-
Positive values can be prefixed with plus sign (+), but it is not mandatory and will not fail the operation.
-
Leading zeros are ignored and will not fail the operation.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "INTEGER",
"tweak": "oneword",
"value": "-2147483647"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "-1052835110"
}
LONG
Tokenize a long data type using the following rules:
-
value range is from –9223372036854775808 to 9223372036854775807
-
Negative values are prefixed with a minus sign (-).
-
Positive values can be prefixed with plus sign (+), but it is not mandatory and will not fail the operation.
-
Leading zeros are ignored and will not fail the operation.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "LONG",
"tweak": "oneword",
"value": "9223372036854775807"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "-3557291484254528418"
}
FLOAT
Tokenize a float data type using the following rules:
-
value range is from 1.1754944 E - 38 to 3.4028235 E + 38
-
Negative values are prefixed with a minus sign (-)
-
32-bit (7 digits)
-
Use case: Graphic libraries due to very high demands for processing powers, and also used in situations that can endure rounding errors.
cURL Example
curl --location --request POST 'http://localhost:8082/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "FLOAT",
"tweak": "oneword",
"value": "-3.4028234663852886E38f"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "-1.14847735E-23"
}
DOUBLE
Tokenize a double data type using the following rules:
-
value range is from 2.2250738585072014 E - 308 to 1.7976931348623158 E + 308
-
Negative values are prefixed with a minus sign (-)
-
64-bit (15-16 digits)
-
Use case: Real values with the exception of monetary values.
cURL Example
curl --location --request POST 'http://localhost:8082/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "DOUBLE",
"tweak": "oneword",
"value": "-3.123456789012345678900123456789012345678900d"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "7.440070193396232E295"
}
DECIMAL
Tokenize a decimal data type using the following rules:
-
Number containing a decimal point and limited to 128-bit (28-29 digits).
-
Negative values are prefixed with a minus sign (-)
-
Use case: Financial applications as it gives you a high level of accuracy and makes it easy to avoid rounding errors.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "DECIMAL",
"tweak": "oneword",
"value": "-123.0000000001"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "-783780695351964454.4903295830"
}
DATE
Tokenize a date using the following rules:
-
Date pattern: yyyy-[m]m-[d]d
-
Leading zero for mm-dd may be omitted.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "DATE",
"tweak": "oneword",
"value": "2021-01-01"
}'
Example Response
{
"uid": "0x0095434475f7141108",
"tweak": "oneword",
"value": "4228-06-24"
}
TIME
Tokenize a time data type using the following rules:
-
Time pattern: hh:mm:ss
-
Leading zero for hh:mm:ss may be omitted.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "TIME",
"tweak": "oneword",
"value": "12:12:12"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "19:26:53"
}
TIMESTAMP
Tokenize a timestamp using the following rules:
-
Timestamp pattern: yyyy-mm-dd hh:mm:ss.fffffffff
-
Fractional seconds (fffffffff) may be omitted.
-
Leading zero for mm-dd, and hh:mm:ss may be omitted.
cURL Example
curl --location --request POST 'https://192.168.0.12:443/api/v1/keys/prf1/tokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "TIMESTAMP",
"tweak": "oneword",
"value": "2021-01-01 12:12:12.123456789"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "oneword",
"value": "2975-08-11 20:04:44.617"
}
Single Item Detokenization
Detokenize single items with an existing PRF key using the Detokenize REST![]() Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API. Detokenizing uses the values and parameters provided in the JSON output of the tokenized data.
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API. Detokenizing uses the values and parameters provided in the JSON output of the tokenized data.
Note
Data may be detokenized by any user of the partition that contains the detokenization key and is authorized to perform this operation. In this guide, we use the same user credentials that performed the tokenization.
URL format: POST <EP URL>/api/v1/keys/:keyId/detokenize
-
Example:
POST https://192.168.0.12:443/api/v1/keys/0x00e42831be94917fad/detokenize?partitionId=test2'
Query params:
-
PartitionID – name of the partition that has the detokenization key.
Path variables:
-
KeyID – UID of the detokenization key. Use the UID from the JSON of the tokenized data.
Body params:
-
dataType – mandatory.
-
tweak – mandatory. Use the tweak from the JSON of the tokenized data.
Note: The same tweak used to tokenize a value must be used to detokenize that value. If the detokenize tweak does not match the tweak that was used for tokenizing that value, the response produces an error.
-
value – mandatory. Use the tokenized value from the JSON of the tokenized data.
-
format – some data types require a specific format – see the examples in Single Item Detokenization.
Note: The same format string used to tokenize a value must be used to detokenize that value. If the detokenize input does not match the format string that was used for tokenizing that value, the response produces an error.
-
maxSize is not required to be specified for detokenization.
Email Address
Detokenize an email address using the body parameters listed above.
cURL Example
curl --location --request POST 'https://92.168.0.12:443/api/v1/keys/prf1/detokenize?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "EMAIL",
"tweak": "1word",
"value": "ghoZR8bGYT5@BEyt6Y1rZbGEbxgK2Cz0vw7G.ir"
}'
Example Response
{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "jane.doe@organization.com"
}
Batch Tokenization
Tokenize multiple items with a PRF key using the TokenizeX REST![]() Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
URL format: POST <EP URL>/api/v1/keys/:keyId/tokenizex
-
Example:
POST https://192.168.0.12:443/api/v1/keys/prf1/tokenizex?partitionId=test2'
Batch params:
-
Is similar to single item tokenization, except for value which is replaced by a JSON array called valueItems.
-
Some data types require a specific format – see the examples in Single Item Detokenization.
Batch response: Contains an array of individually tokenized items – see the example below.
Email Address
Tokenize multiple email addresses.
cURL Example
curl --location --request POST 'http://localhost:8082/api/v1/keys/prf1/tokenizex?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "EMAIL",
"tweak": "1word",
"valueItems": [
"jane.doe@organization.com",
"john.doe@company.com"
],
"maxSize": 40
}'
Example Batch Response
[
{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "ghoZR8bGYT5@BEyt6Y1rZbGEbxgK2Cz0vw7G.ir"
},
{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "DHvaX05a@xOS8czElN9svrzUTqvL14lu7GJ7.mc"
}
]
Batch Detokenization
Detokenize multiple items with an existing PRF key using the DetokenizeX REST![]() Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
Representational State Transfer (REST) - an architectural style that defines a set of constraints and properties based on HTTP. Web Services that conform to the REST architectural style, or RESTful web services, provide interoperability between computer systems on the Internet. API.
URL format: POST <EP URL>/api/v1/keys/:keyId/detokenizex
-
Example:
POST https://192.168.0.12:443/api/v1/keys/0x00e42831be94917fad/detokenizex?partitionId=test2'
Batch body params:
-
Is similar to single value detokenization, except for value which is replaced by a JSON array called valueItems.
-
Some data types require a specific format – see the examples in Single Item Tokenization.
Batch response: Contains an array of individually detokenized items – see the example below.
Email Address
Detokenize multiple email addresses.
cURL Example
curl --location --request POST 'http://localhost:8082/api/v1/keys/prf1/detokenizex?partitionId=test2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic dXNlckB0ZXN0MjpQYXNzd29yZDEh' \
--data-raw '{
"dataType": "EMAIL",
"tweak": "1word",
"valueItems": [
"ghoZR8bGYT5@BEyt6Y1rZbGEbxgK2Cz0vw7G.ir",
"DHvaX05a@xOS8czElN9svrzUTqvL14lu7GJ7.mc"
]
}'
Example Batch Response
[
>{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "jane.doe@organization.com"
},
{
"uid": "0x00e42831be94917fad",
"tweak": "1word",
"value": "john.doe@company.com"
}
]